LLaMA-Factory可以使用零代码命令行与Web
UI轻松微调百余种大模型,对于想快速体验一下训练的同学非常友好。
参考信息
github
online-doc
mac-llama-factory例子
下载并安装
[!IMPORTANT] 此步骤为必需。 😅
下载源码,创建环境,安装依赖
1
2
3
4
5
6
7
| git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n py310 python=3.10
conda activate py310
pip install -e ".[torch,metrics]" --no-build-isolation
|
Tips:
- 建议使用python 3.10版本,看readme的推荐软硬件依赖
- 我的Mac芯片:Apple M1 Pro,macOS:13.4
安装依赖可能遇到的坑
- 找不到Cython模块 → 单独安装下
pip install Cython
- ERROR: Failed building wheel for av → 单独安装下
conda install av -c conda-forge
整体安装有惊无险,成功后提示安装的库如下图:

下载模型
建议用huggingface-cli提前下载模型,速度更快
1
| huggingface-cli download --resume-download Qwen/Qwen2.5-0.5B-Instruct
|
启动WebUI
这里使用LLaMA Board 进行可视化微调,执行如下命令:
成功启动后,看gradio地址 http://localhost:7860/
页面和readme的例子一样,如果读英文慢,可以改语言为zh
加载模型并体验问答
前面步骤我们下载了模型
Qwen/Qwen2.5-0.5B-Instruct,这次加载这个模型(忽略途中的lora的检查点路径哈)
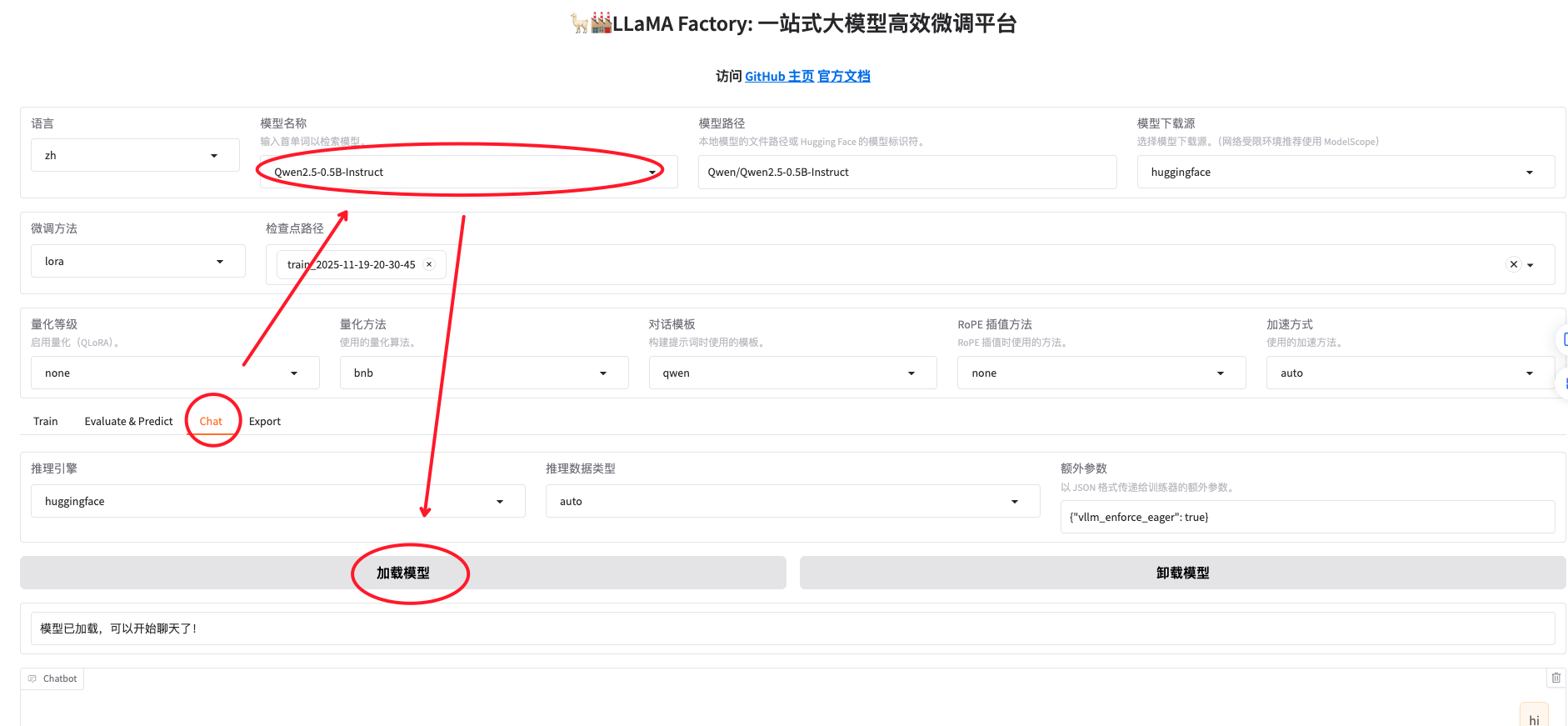
问模型你是谁
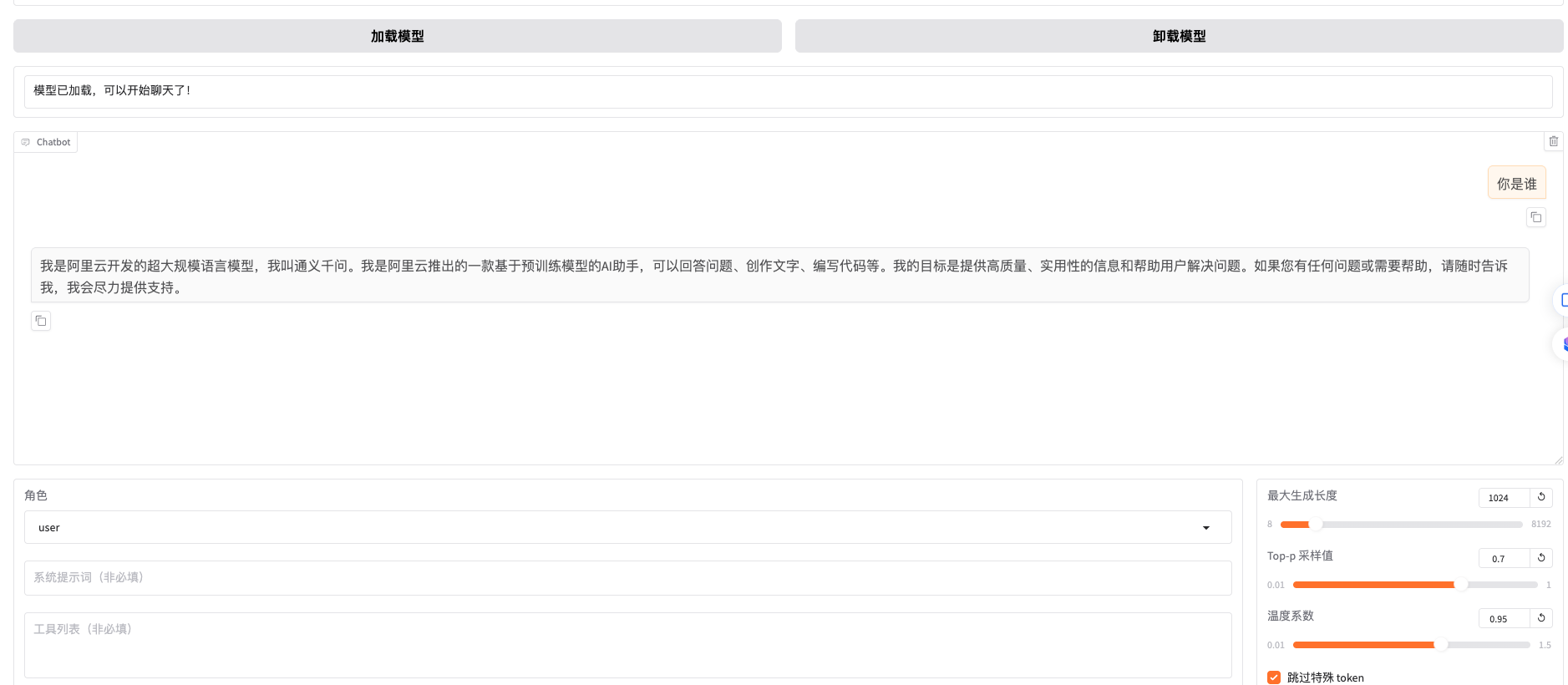
使用LoRA训练模型自我身份认知
正式场景不推荐训练自我身份认知,把身份认知信息放在system
prompt更有效。
准备数据集
注意:使用自定义数据集时,请更新 data/dataset_info.json 文件。
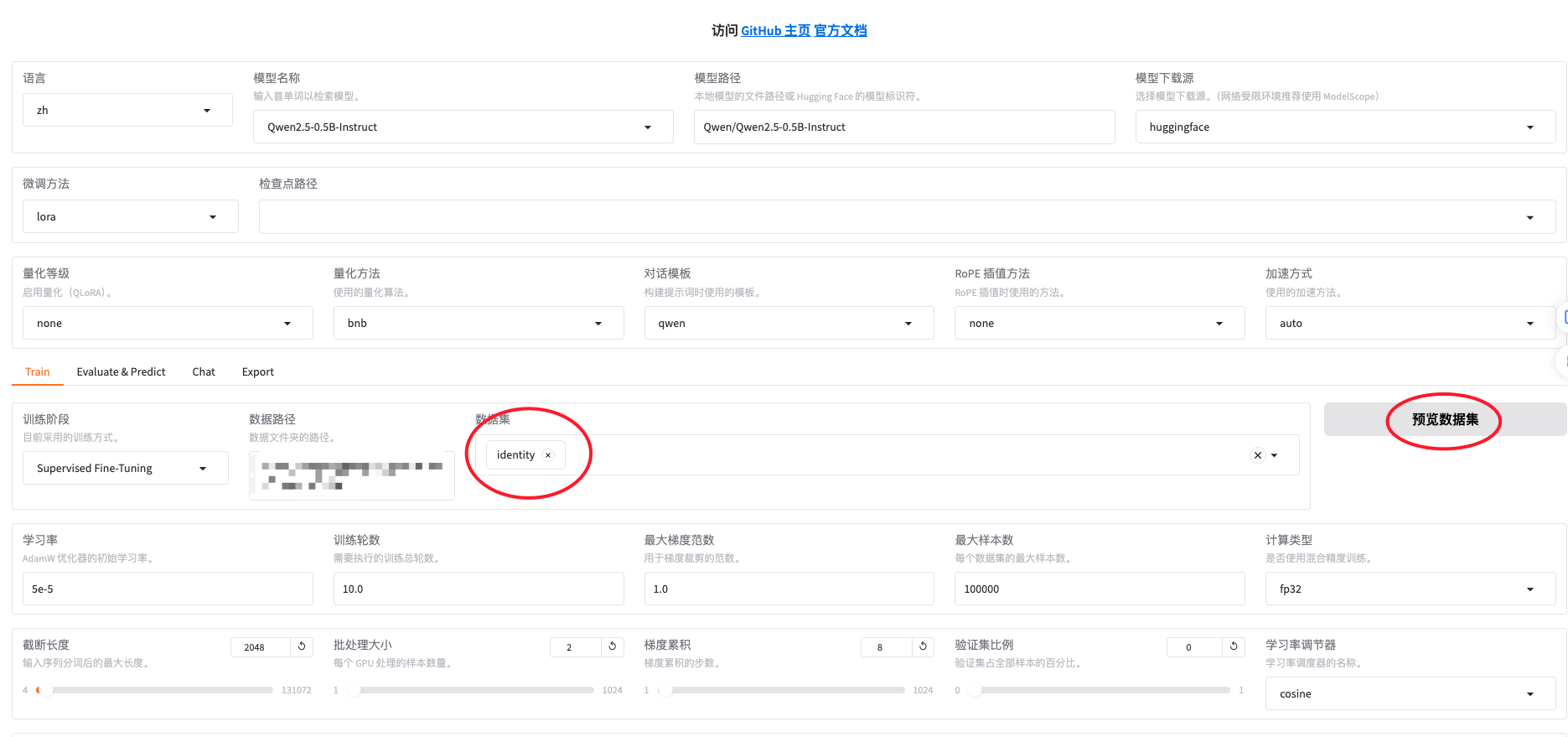
identity数据集在
LLaMA-Factory目录下的data目录中,data的目录如下(贴图比较麻烦,看命令行输出吧)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| tree
.
├── README.md
├── README_zh.md
├── alpaca_en_demo.json
├── alpaca_zh_demo.json
├── c4_demo.jsonl
├── dataset_info.json
├── dpo_en_demo.json
├── dpo_zh_demo.json
├── glaive_toolcall_en_demo.json
├── glaive_toolcall_zh_demo.json
├── identity.json
├── kto_en_demo.json
├── mllm_audio_demo.json
├── mllm_demo.json
├── mllm_demo_data
│ ├── 1.jpg
│ ├── 1.mp3
│ ├── 1.mp4
│ ├── 2.avi
│ ├── 2.jpg
│ ├── 2.wav
│ ├── 3.flac
│ ├── 3.jpg
│ ├── 3.mp4
│ ├── 4.mp3
│ └── 4.mp4
├── mllm_video_audio_demo.json
├── mllm_video_demo.json
├── reason_tool_use_demo_50.jsonl
├── v1_dpo_demo.jsonl
├── v1_dpo_demo.yaml
├── v1_sft_demo.jsonl
├── v1_sft_demo.yaml
└── wiki_demo.txt
|
看一眼identity数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| {
"instruction": "您好",
"input": "",
"output": "您好,我是 {{name}},很高兴为您服务。有什么我可以帮您解决的问题或者需要我提供的帮助吗?"
},
{
"instruction": "你是谁",
"input": "",
"output": "您好,我是由 {{author}} 发明的 {{name}}。我可以为您提供多种多样的服务,比如翻译、写代码、闲聊、为您答疑解惑等。"
},
{
"instruction": "你是谁?",
"input": "",
"output": "您好,我是 {{name}},一个由 {{author}} 发明的人工智能助手。我可以回答各种问题,提供实用的建议和帮助,帮助用户完成各种任务。"
}
|
配置训练参数并训练
如上图界面选loRA,3个Epoch训练效果不太好(数据少91*3),我按10个Epoch训练的
点界面下方的预览命令,输出如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path Qwen/Qwen2.5-0.5B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset identity \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 10.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--enable_thinking True \
--report_to none \
--output_dir saves/Qwen2.5-0.5B-Instruct/lora/train_2025-11-19-20-30-45 \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
|
训练60Step后,loss收敛到1左右,大概用了半小时

训练结束日志(3epoch版本)
1
2
3
4
5
6
7
8
| ***** train metrics *****
epoch = 3.0
num_input_tokens_seen = 19656
total_flos = 39793GF
train_loss = 0.0
train_runtime = 0:00:00.00
train_samples_per_second = 111984.84
train_steps_per_second = 7383.616
|
Tips:
训练没有使用MPS,仍然走的CPU,先走CPU亦可,能走通。
1
| [INFO|2025-11-19 21:03:53] llamafactory.hparams.parser:468 >> Process rank: 0, world size: 1, device: cpu, distributed training: False, compute dtype: None
|
ValueError: Your setup doesn't support bf16/gpu. →
!!精度选fp32,不选bp16,也不要选fp16,敲重点,CPU模式关键配置
如上图界面选loRA,3个Epoch训练效果不太好(数据少91*3),我按10个Epoch训练的
训练后体验和评估
体验:训练后在chat页面,选择lora模型,询问你是谁,和我们的训练集结果一样,和基模的回答不一样了,训练生效。
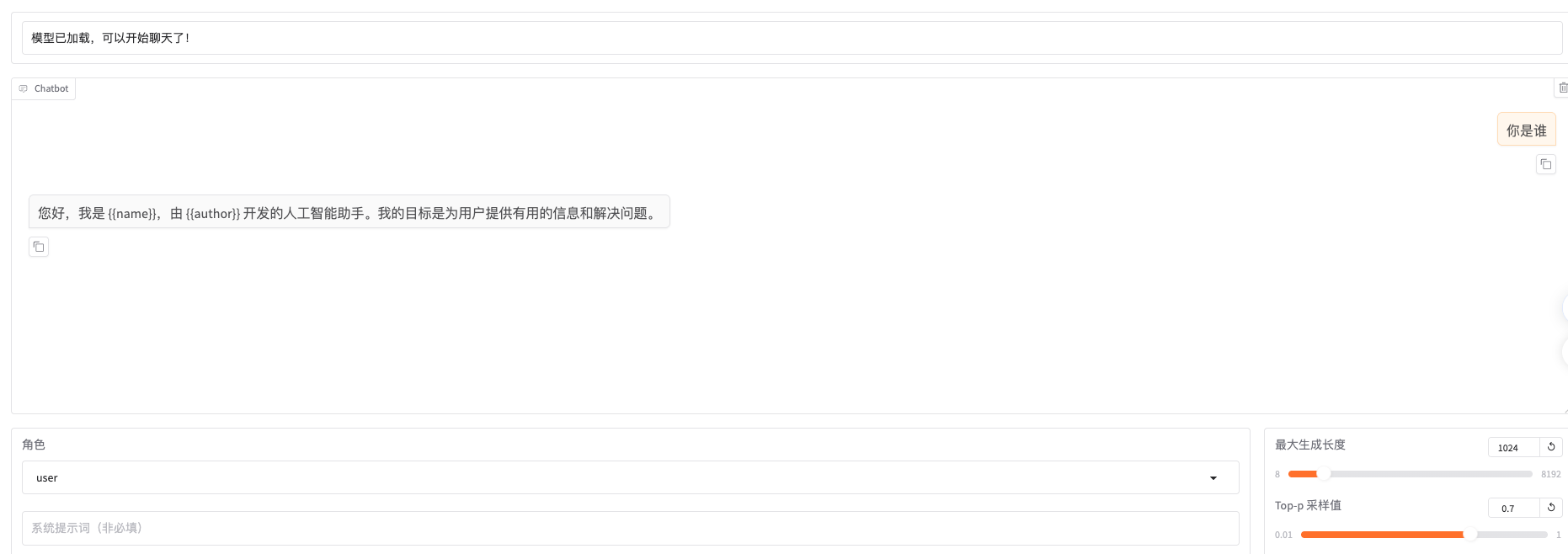
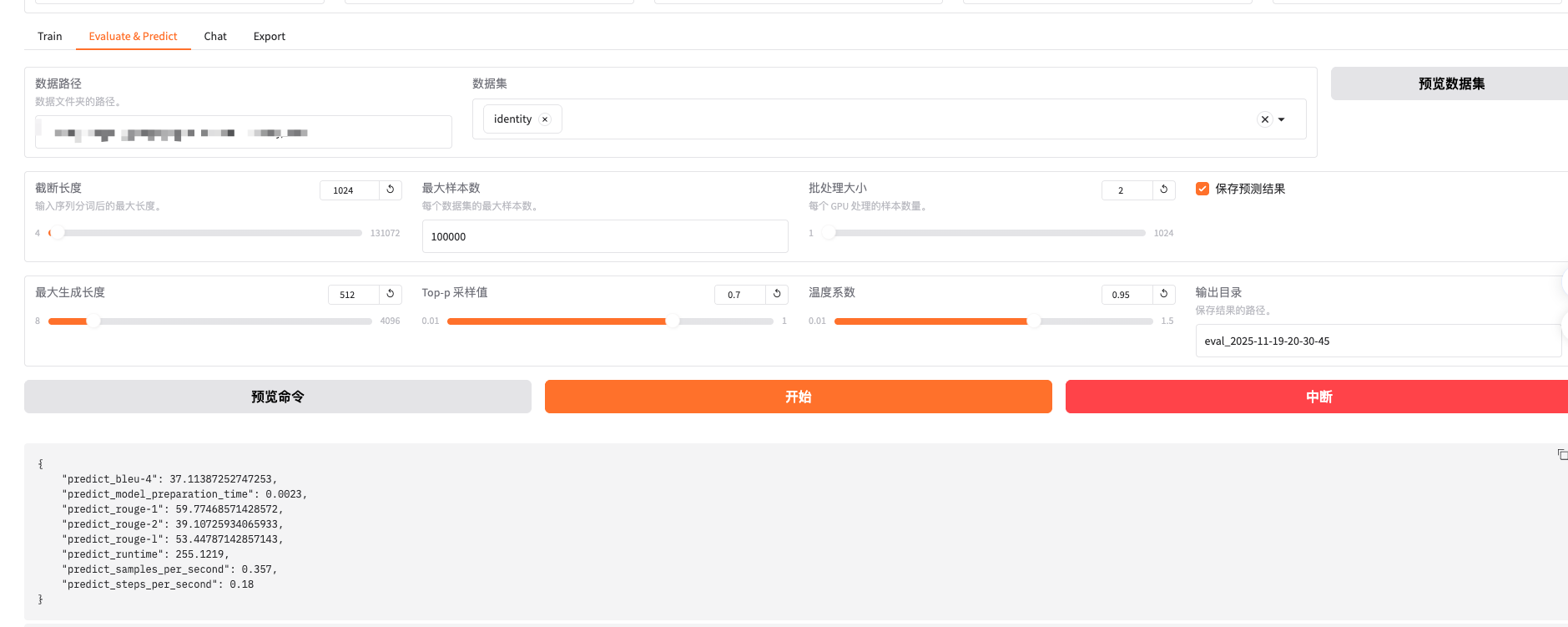
评估页面,还是以identity作为评测集(应该用单独的评测集),简单跑下5分钟后,生成基础的指标,比如bleu、rouge等效果指标和一些性能指标。只有基本指标,指标项较少。
模型导出和推理
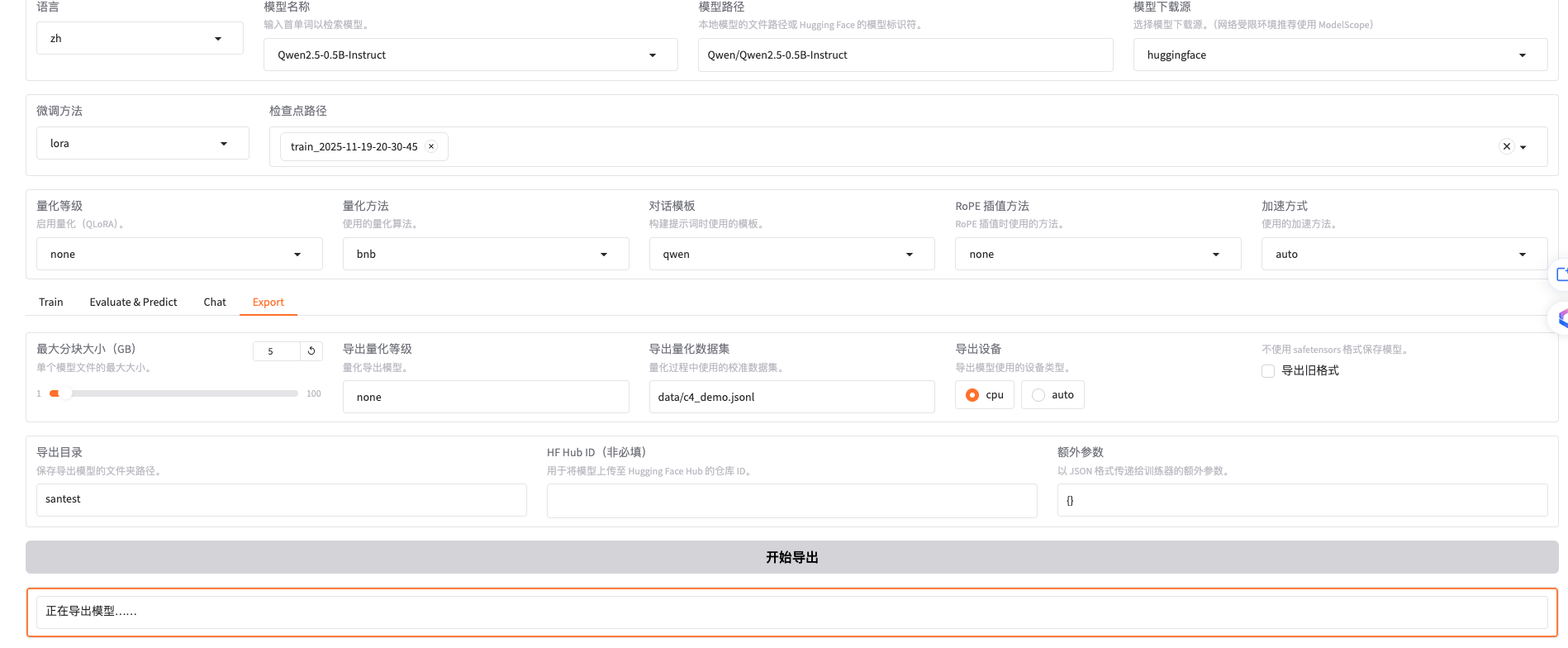
导出文件目录santest,导出成功后界面如下:
1
2
3
4
5
6
7
8
9
10
11
| Modelfile 464
added_tokens.json 605
chat_template.jinja 2507
config.json 1226
generation_config.json 242
merges.txt 1671853
model.safetensors 1976163472 #1.9G 就是fp32的模型文件
special_tokens_map.json 613
tokenizer.json 11421896
tokenizer_config.json 4712
vocab.json 2776833
|
然后重新加载看看是不是咱们lora好的,做个问答试试
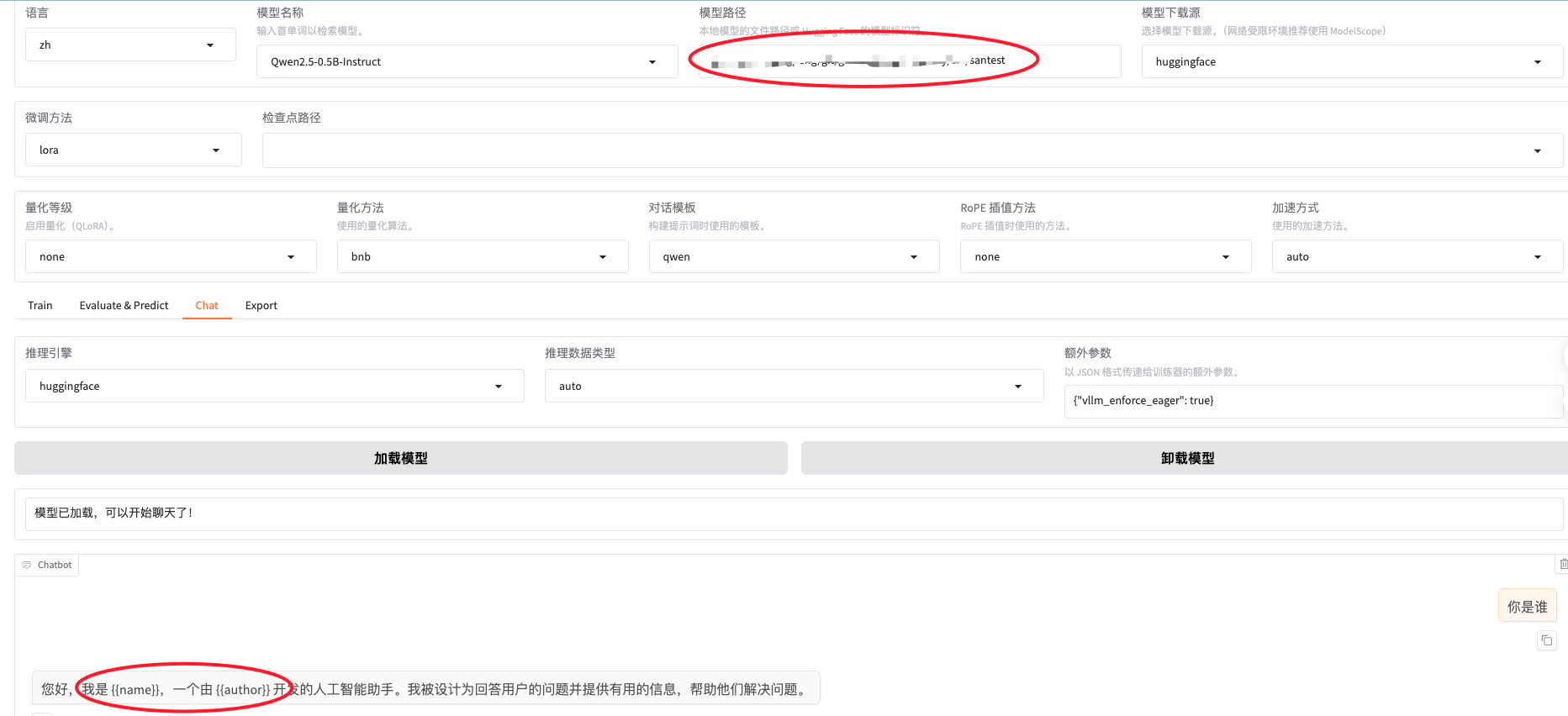
总结
LLaMA-Factory是个很好的个人电脑界面化体验训练推理流程的应用,期望大家能够一步一步的从入门到xx,从面子到里子,因热爱而学习,因学习更热爱。